Some broadcasters dream about being able to pull up to a remote venue, plug a camera into the Internet, and send live video and audio back to the station. This scenario is not too far from reality, but there are still some hurdles to overcome. Several large broadcasters have conducted streaming tests over the public Internet. The results of these tests have been mixed. The good news is that it does seem to be possible to stream broadcast-quality video over the Internet. The bad news is that the public Internet has some behaviors that are impolite to video, to say the least.
Nevertheless, real progress has been made in this area. Generalized multiprotocol switching (GMPLS) provides traffic-engineering (TE) capabilities for Internet-protocol (IP) networks. TE has been a critical component of ATM networks from the beginning, and is the basis for quality-of-service (QoS) delivery. Simply put, QoS parameters allow equipment manufacturers and users to make basic assumptions about “how bad (or how good) the connection can be” between two nodes. The parameters they might specify include those with which video engineers are familiar, such as delay, jitter and wander. In the past, it was difficult to obtain any specific QoS out of an IP network. But IP equipment manufacturers have been working hard to address this issue, and GMPLS is one technology that allows the engineers to nail down the parameters of the network.
What's the problem?
But before we go into possible solutions, let's look into the problem. What is wrong with using a traditional IP network as it stands? For one thing, when you make a connection with a server providing IP streaming video over the Internet, there is no guarantee of how long the delay will be from the point of origin across the network. Furthermore, that delay may change during the time that the feed is taking place. You have probably seen the effects of this as an Internet video feed halts while the buffer reloads. In practice, it is almost impossible to design a streaming asynchronous video decoder when you do not know how bad this delay could get. Another issue is that packets may take different paths over the Internet. In fact, there is no guarantee that the destination will receive packets in the same order the originator sent them. Additionally, the best path available may become unavailable without warning. One of the strengths of the Internet is that, if this path goes down, traffic will be dynamically rerouted around the outage. This strength means that there is no critical path between any two nodes on the network. However, this flexibility plays havoc with any sort of synchronous transmission where timing across the network is an important component in delivering the quality of service required.
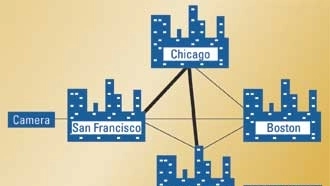
Figure 1. In this hypothetical Internet network, the dark lines represent high-speed links. When streaming over IP, there’s no guarantee that any packet will take the same path between points.
An example may help to highlight these issues. Let's look at a hypothetical Internet network connecting the cities of San Francisco, Chicago, Dallas and Boston, shown in Figure 1. Let's assume for the moment that there are high-speed links between San Francisco and Chicago, and between Chicago and Dallas. You have a theoretical IP-capable camera in San Francisco and a system capable of receiving video over IP and displaying it in Dallas. Let's also assume that you are using the generic Internet with no special protocols — just TCP/IP.
Direction and delay
First of all, even thought it might seem logical, there is no guarantee that the packets will be sent directly from San Francisco to Dallas, even though there is a direct path between two cities. And even though a high-speed path exists from San Francisco via Chicago to Dallas, there is no guarantee that even one packet would take this route. This is because the Internet is a fully meshed network. It is dynamic, and the exact routing between any two points on the Internet may change packet by packet as loading, circuit outages and other factors come into play. When our hypothetical feed starts, the “best” path may be from San Francisco via Boston to Dallas. Just because there are high-speed paths between other cities does not mean that there will be available bandwidth when a given packet needs to be sent.
Now let's consider delay. Even if we have a constant path from San Francisco to Dallas, the timing on a packet-by-packet basis will be constantly changing depending upon queuing, switching and other delays across the network. This is because constant timing across the network was not a critical design criterion for the Internet. Obviously, if the packet never makes it to its destination, this is a problem. But, for most data traffic, it does not matter whether the packet makes it there in 5ms or 500ms.
Outage and rerouting
As you may know, the Internet started out as a project to link government facilities together. Messages had to get across the network, even in the event of an attack. The network was designed so that a failure of one link would not take down the whole network. This rerouting capability is still a core characteristic of the Internet. And while this self-healing capability is a desirable trait, it can play havoc with network timing. Let's refer back to our example. If we are in the middle of a feed, and the path is from San Francisco via Chicago to Dallas and the Chicago-to-Dallas leg has a momentary outage, the traffic might be dynamically rerouted to Boston and then to Dallas. This new path might stay active for a second or two and then, when the Chicago-to-Dallas leg comes back up, packets would again be received from Chicago.
Gaps and rearranged packets
Figure 2 illustrates some possible effects from this momentary outage and reroute. We start with packets coming in from Chicago. When the link from Chicago to Dallas goes down, a gap forms — caused by the time it takes the network to reroute the packets to Boston, plus the additional transit delay across the longer network path.
Figure 2. In the event of a temporary network outage, packets may be delayed and reach the receiver out of order.
In a matter of moments, the traffic is rerouted and packets begin arriving again, but now they are coming from Boston. As soon as the link comes back up, a packet is received from Chicago. Unfortunately, this is packet #6, but the receiver was expecting packet #5. Shortly thereafter, packet #5 arrives from Boston. The packets were reordered because of switching and transit times across the network. As you can imagine, the impact of reordering on receiver output timing might be extreme. These sorts of delays and reordering happen every day over the Internet and things work just fine. This is because TCP is responsible for reordering packets and requesting that packets that got lost along the way be resent. For most data applications, this system works, and it has served us well for many years.
You might be able to fix the problems pointed out thus far with a huge buffer. If you have a 10-second buffer in your receiver, then you can deal with all sorts of problems across the network. But there are two issues with this approach for broadcast. First, a 10-second delay in network transmission makes the circuit unusable for any two-way live interview purposes, a common electronic-news-gathering (ENG) application. Second, since there are no service-level guarantees across the Internet using most technologies, there is no guarantee that a 10-second buffer, or even a 100-second buffer, would provide the sort of reliability broadcasters need.
Possible solutions
The issues presented so far are well known in the Internet community, and various groups have been working on a number of solutions. To make a long story short, a lot of progress has been made in providing traffic-engineering capabilities over the public Internet. Traffic engineering allows the network operators to control the behavior of the network, and the flow of packets over the network, so that delays become consistent and so that the consequences of a failure in the network are predictable. The single biggest hurdle to be overcome (and perhaps this problem has already been solved in a laboratory somewhere) is the issue of dynamic rerouting. Until someone invents a technology that can predict the future — predict when and where a network component will fail — there will be some impact on the receiver as the network heals itself. But it seems that the network's self-healing capability is well worth the occasional hits caused as traffic is routed around the failed component.
Brad Gilmer is president of Gilmer & Associates, a technology consulting firm. He is also executive director of the Video Services Forum and executive director of the AAF Association.
Send questions and comments to:brad_gilmer@primediabusiness.com
