Backup systems for television facilities began to appear almost immediately after paid advertising. Loss of commercials meant loss of revenue, and it did not take people long to figure out that having a backup plan makes financial sense.
Today, almost every television facility has some sort of backup plan. But as IT-based facilities become the norm, are new backup strategies required? Video servers are now employed in approximately 70 percent of all television facilities. For critical applications, engineers frequently specify mirrored or duplicate servers. Given an IT infrastructure, are other strategies available?
Full redundancy
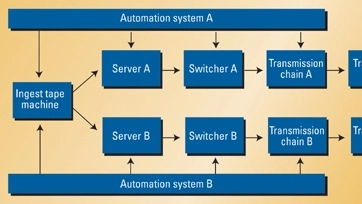
For the really big guys, full redundancy is frequently employed. If they need one server, they buy two. If they need one switcher, they buy two. The operations are driven by two completely separate automation systems, with a single ingest process used to populate the video servers (see Figure 1).
Figure 1. Simplified diagram of a fully redundant system
Fully redundant systems seem easy to build: design your facility and then multiply it by two. But like almost anything in life, things get a little more complicated. It takes a lot of hard work to design a fully redundant system that really is redundant. For example, you might design a completely separate transmission path, but run all the equipment from a common house sync generator. Furthermore, over time, redundant systems have a way of becoming intertwined as facilities are modified or expanded. In the end though, fully redundant systems may make sense for some people.
If you don't have an unlimited budget, how can you backup your systems — especially as we move towards IT-based television? In many cases, while it may not be possible to build a totally redundant facility, it is not prohibitively expensive to build a redundant IT infrastructure. This is because the cost of most off-the-shelf IT equipment is so low. In Figure 2 on page 50, a server is fitted with two Ethernet cards. These cards feed two separate Ethernet switches. From there, the redundant networks are supplied to PCs fitted with redundant Ethernet cards. This example is extremely simple and, of course, the server is a single point of failure. However, the total cost of the redundant network shown in this figure is about $400. Building redundant Ethernet networks is a topic for another column. But, for now, rest assured there are many different ways to configure a network so that there is no single point of failure.
High reliability, high availability and fault tolerant
When considering backup strategies for IT, you may run into some unfamiliar terms, or terms that are used interchangeably, but have subtly different meanings.
There are three approaches engineers can take to building bulletproof IT-based television systems: high reliability, high availability and fault tolerant.
High reliability means that the component or system has a high mean time between failures (MTBF). The system can run a long time before failing. Using high-quality components, overrated parts and building a high-quality device usually achieves high reliability. Highly reliable devices may undergo extensive testing including “shake and bake,” in which the assembled systems are subjected to extremes of temperature and vibration. Highly reliable systems are usually built and tested by a single vendor. This is to assure that the system and all its components meet the design specifications. Needless to say, highly reliable systems can have a high price tag but, in some cases, this solution can be the most economical, depending upon the cost of outages. Furthermore, it may be that the functionality or performance you require is only available in a high-reliability device.
Figure 2. Redundant Ethernet can provide backup at minimal cost.
The second approach, high availability, uses a different strategy. The point is not to prevent failures, although high-quality components can be used. Instead, a designer uses off-the-shelf components to design a system so that a single failure has little impact. An example of a high-availability disk system might include multiple just-a-bunch-of-disks (JBOD) arrays, perhaps RAID configured, perhaps not. The costs of the arrays are low enough that the whole array can be duplicated economically. Another example might be to design a network with two completely separate Ethernet systems. The servers and clients might have two Ethernet cards in them instead of one. High availability typically takes advantage of the low price of consumer computer hardware. It might seem cumbersome to put together two completely separate Ethernet networks. But from a cost standpoint, Ethernet is practically free these days, unless you are talking about the very high-speed technology.
The effect of using this approach is impressive. If two devices are combined in a hot standby configuration, the MTBF of the total system increases by the square of the individual MTBF numbers! Furthermore, the cost of off-the-shelf equipment can be substantially lower than equipment manufactured for high reliability. But, as pointed out above, off-the-shelf equipment may not have the functionality or performance you require.
Don't get the wrong idea — high-availability systems are typically well engineered. They can provide excellent recovery from faults, and may provide a lower overall cost than high-reliability systems. But, typically, high-availability systems may have a higher fault rate than fault-tolerant systems, although this depends entirely on decisions made by the system designers.
In the fault-tolerant approach, systems are designed so that a single fault will not cause a total system failure. Fault-tolerant systems frequently include things like dual power supplies, redundant disks, dual disk controllers and automatic changeover software. Many fault-tolerant systems are designed so that backup devices go on-line without any service interruption. The only way you know there has been a failure is by checking status monitoring and alarms. Therefore, checking for alarms on fault-tolerant systems is critical. If you lose a power supply in a dual-power-supply unit, the output of the device will be unaffected. However, if you fail to detect the problem and subsequently lose the other supply, you could be off the air.
High-reliability systems may come with 24-hour support that is geared for the IT and business world. This support can be costly, but it can really be a lifesaver in critical applications. High-availability systems may not come with this level of support (and associated cost). This can be a good thing or a bad thing, depending on your expectation.
The choice of high reliability, high availability or fault tolerance may be as much philosophical as it is economic or technical. Some users feel much more comfortable with systems that are designed as a whole, and that have IT-type support. Others feel more comfortable with systems built out of readily available components that they can easily see and understand. When considering IT-based systems and the issue of reliability, be sure to think about your own engineering philosophy and buy the appropriate solution.
Backup the database
Imagine getting a call to come to your facility in the middle of the night. The automation system seems to be up, but it is unable to find any commercials or programs. You have a small system; perhaps it stores a few thousand items. After some research, you determine that the database in the automation system has become corrupted. Depending on what has gone wrong, you might have things back on in a mater of minutes. But without a proper backup strategy, the first thing you should do is go put on a pot of coffee — it's going to be a long night.
How very true is the old adage that you really don't appreciate what you've got until it's gone. If you have ever lost a database in a modern television facility, you know how true this saying is. Several years ago, the author lost the database in a large, tape-based robotic system. Over 1000 tapes were spread out on the floor, and engineers and operators scrambled to locate the correct tapes and get them back in the machine before they were needed for air. It was an amazing three or four hours, but the staff managed to get the system back on the air. As that operation has moved to IT-based television, the scene described above is in the past. Pulling tapes is no longer an option.
Since the database is such a critical part of almost any on-air operation, having a backup plan and using it is critical. It may be that tape backups are the best option. There are many tape-backup systems available on the market. It almost doesn't matter what option you choose, just as long as you have something in place. Systems with tape changers now make it easy to rotate tapes on a regular basis without having to remember to physically change a tape. For critical applications, you have several options. Modern databases allow you to mirror the database onto separate disks in the same server, or even mirror entire servers. There are many choices, but the most important factor is to put a backup plan in place so that you won't have to pick up the pieces after a disaster.
Brad Gilmer is executive director of the AAF Association and technical moderator of the Video Services Forum.
Send questions and comments to:brad_gilmer@primediabusiness.com
